.NET Core ORM建模基本须知
Copyright Notice: This article is an original work licensed under the CC 4.0 BY-NC-ND license.
If you wish to repost this article, please include the original source link and this copyright notice.
Source link: https://v2know.com/article/320
继上一讲:[ORM]如何在目框架为.NET Core 2.1的时候使用EntityFrameworkCore
这一讲,主要讲你在创建Model需要知道的东西。
一
通常情况下,你的Model写在一个文件下。
以我的博客为例,我选择的是把模型放在了Blog.cs文件里面。
二
从最主要的产物开始写。
以我的博客为例,我选择先写Blog类。
三
每个类的第一个字段为Id。
以我的博客为例,我的Blog类的第一个字段为Id,这么写,在不加任何特性的情况下,会让其成为主键,这也是我们想要的结果。
四
关于外键,先在主类里面写你的副类的名字,然后命名,这样ORM会理解为以副类的Id作为外键。
以红框标记为例:
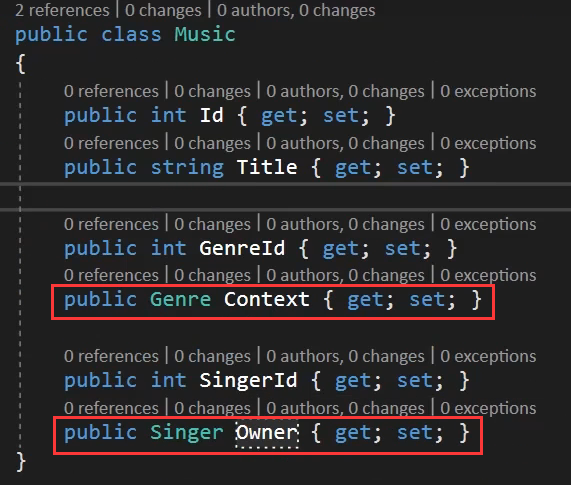
Genre和Singer分别是两个外键,它们各自的主键Id分别是Musics这张表的外键。
五
可被枚举类型。
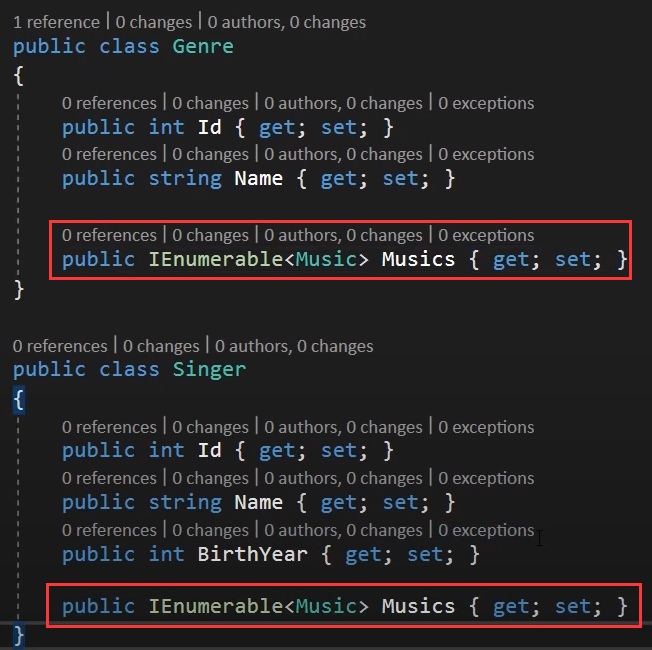
如图所示,红框标记处就是枚举写法。
它的作用是,确定1对N还是N对N的关系,举我博客例子:
我的博客会有分类专栏,我可以通过查询Blogs表得知该Blog属于哪一个专栏,但到此为止,这是外键给你实现的东西,你可以因为一篇Blog而查到Genre里的详细信息;
如果反过来,我们想要由一个类别,而查到对这个类别下面所有的博客,那我们就应该用可被枚举类型。
注意,它并不会在数据库的表中创建一个叫Musics的字段,这个字段是用来给框架理解的。
六
注意书写。
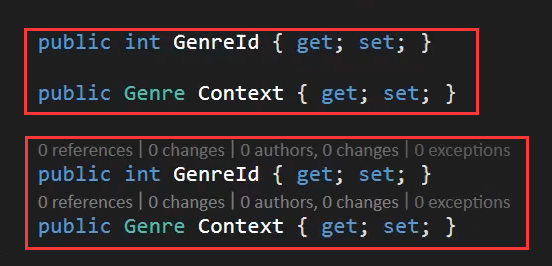
红框标记的两句为一个整体。
这才是一个可被ORM框架理解的外键。
七
枚举类型必须得是外键所提及的类。
简单解释一下,以上述Musics类为例,Genre和Singer的Id是被使用的外键,那么你可以在Genre或Singer里面定义一个可被枚举的字段Musics:
public IEnumerable<Music> Musics {get;set;}
Extra
在我的开发过程中,我认知到可以通过lambda表达式从任意Blog中获得其Genre,再以Genre直接获得对应Genre的所有Blogs的全部字段,注意,不是说遍历出该Genre的所有Blog的Id,而是直接获得相当于直接查询Blogs表的结果。
一般情况下,我们会选择遍历Blogs表来找到符合GenreId的Blog的Id,然后再用Id去查询实际的Blog,而可被枚举类型的作用是直接帮你省略了一次遍历再查询的过程,并且不单单是省略,甚至优化了性能!因此,我是非常建议使用可被枚举类型的。
这其实也是一个最基本的设定,当你把分类专栏里面的任意一个分类删除,那么这个分类所对应的所有Blogs都将被删除,ORM会正确理解你想表达的意思。
参考资料:
[1] 紧急情况下在5分钟内做完毕设 - ASP.NET Core入门之最快速做一个音乐商店出来
This article was last edited at